It’s finally Summer, so it’s time for a new major version of Numbas. This year I’ve been working on diagnostic testing, and other adaptive assessments. There are also some new question-level features, improved accessibility, and some new features in the LTI tool.
Numbas runtime
I’ve tagged v6.0 of the Numbas runtime on GitHub.
Diagnostic testing
At Newcastle University, for several decades stage 1 engineering students have sat the DIAGNOSYS test, a computer-based assessment to identify any missing areas in their presumed maths knowledge. DIAGNOSYS was designed by my colleague John Appleby, and is delivered through a Windows 3.1 (!!) program that John wrote. I’ve always wanted to find a way to reimplement DIAGNOSYS in Numbas.
The main idea underlying DIAGNOSYS is the knowledge graph: a network of topics, linked by dependency. For example, “add/subtract algebraic fractions” depends on “add/subtract numeric fractions”. When the student sits the test, they’re shown questions on each of the topics to be assessed. If they get the question right, then the system infers that they’d also be able to answer questions on linked topics, so marks them as “passed” too, and doesn’t show them to the student. If they get the question wrong, the system infers that they wouldn’t be able to answer question on topics depending on this one, so marks them as “failed” and doesn’t show them to the student. Once every topic is marked as either “passed” or “failed”, the test ends.
This model is quite simple, and many other models for adaptive assessment exist: item response theory, using answers to update a Bayesian model of the student’s knowledge; mastery, where every task must be passed before moving on to the next one; among others.
My aim for the past year was to design a framework for implementing not just DIAGNOSYS but any adaptive model I could think of. I’ve got to the point where DIAGNOSYS works, and I have the beginnings of a mastery model, but I’d really like some input from others. Designing these tests takes a lot of time, and I think they require a few rounds of improvement after being tested by students.
So there’s now a “Diagnostic” navigation mode for exams. A new “diagnostic” tab appears in the editor, where you can set up a knowledge graph by defining topics and their relationships with each other. Each topic corresponds to a group of questions, which you can fill up in the normal way.
The adaptive model is powered by a “diagnostic algorithm”, which is a script in a similar format to the marking algorithms for parts. It’s in charge of selecting the questions to show to the student and giving feedback both during the test and once it’s finished. The algorithm can offer the student a choice of actions once they’re finished with a question: the DIAGNOSYS algorithm offers a limited number of retries when the student gets a question wrong, while a more complicated algorithm could offer to increase or decrease the difficulty level.
There are still a few things I’d like to add to this feature, such as easy to use settings inside the editor and maybe a visualisation of the knowledge graph, but I’d like to check I’m on the right track before going any further. So please give it a go, and let me know what you think!
You can try DIAGNOSYS in Numbas now, released under the Creative Commons Attribution licence, or read the documentation on the diagnostic mode.
Case-sensitivity and constants
My colleagues at Newcastle have written a lot of Numbas material this year, and I suppose I shouldn’t have been surprised at how many notational changes they want to make.
First, quite a few people have asked to change the meanings of constants.
A physicist wanted to use the letter $e$ as a variable representing eccentricity, rather than the constant which is the base of the natural logarithm. At the same time, a pure mathematician teaching group theory wanted to use $e$ for the empty word. Other colleagues in engineering have asked to use $j$ for the imaginary unit, rather than $i$.
The hard part in allowing these changes wasn’t in parsing or evaluating expressions but in displaying them: the code that produces the LaTeX for an expression or a number needs to know what the meaning of each of the currently defined constants is.
Now each question has a Constants tab inside Extensions & scripts where you can turn the built-in constants on or off, and define new ones.
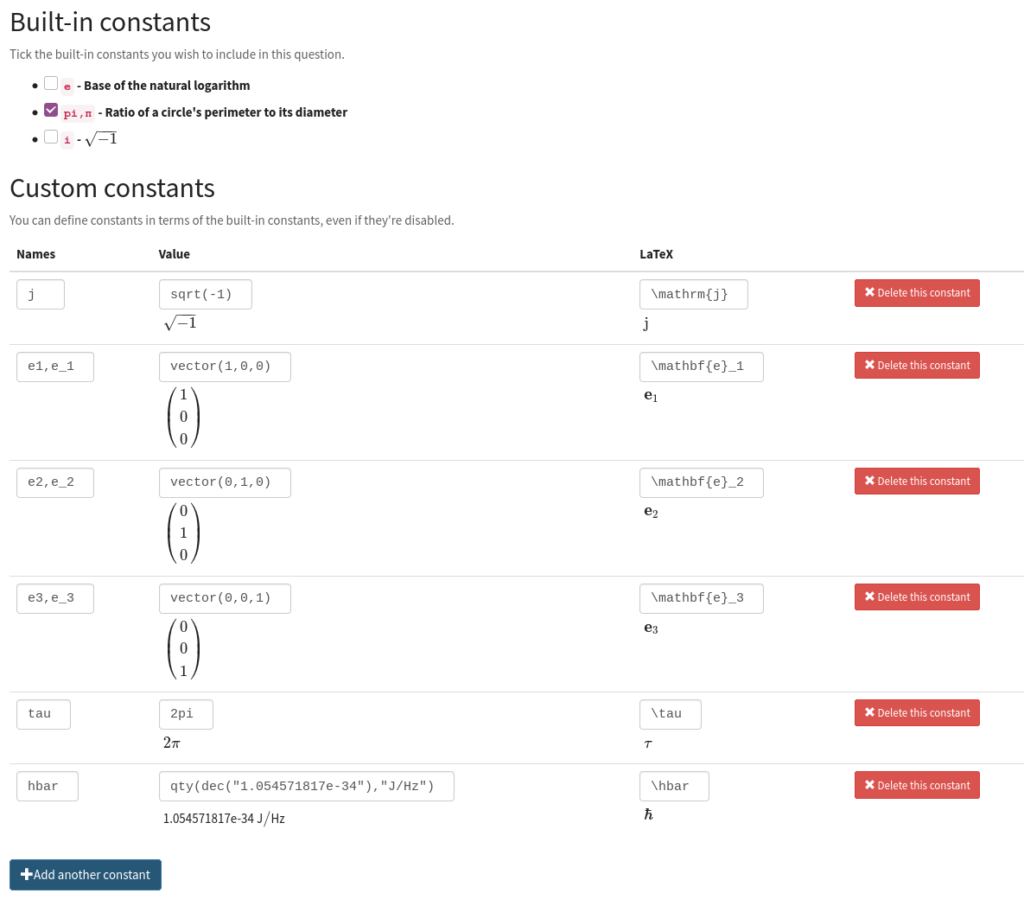
The constants you define are available everywhere in a question: in variable definitions, in \var and \simplify, and in the answer to mathematical expression parts.

I’ve collected some questions demonstrating how to use custom constants in the demos project.
The second notational change, that is really down to a foolish design decision ten years ago, is that the physicists wanted to make expressions case-sensitive, so that a * A isn’t the same as a*a. Again, this required quite a lot of code to change, and careful testing that there wasn’t anything relying on case-insensitivity.
Mathematical expression parts now have an option “Expression is case-sensitive?”. If that’s ticked, then names which are not the same case are not considered equivalent.
Variable overrides
While developing the mastery algorithm, I wrote a numeracy test using it in order to discover what features it’d need. I realised that I had a few topics where I wanted to ask effectively the same question several times, but with a difficulty progression.
As an example, I had a topic on addition. I wanted to first ask the student to add two single-digit numbers, then two-digit numbers without a carry, and so on, gradually getting more complicated.
I realised that if I could set the values of question variables for each instance of the question in the exam, I would just have to rewrite one question of the form “Add $a$ and $b$”.
So now each variable defined in a question has a checkbox “Can an exam override the value of this variable?”. If it’s ticked, then in the exam editor each instance of that question shows a text box where you can write a value for that variable.
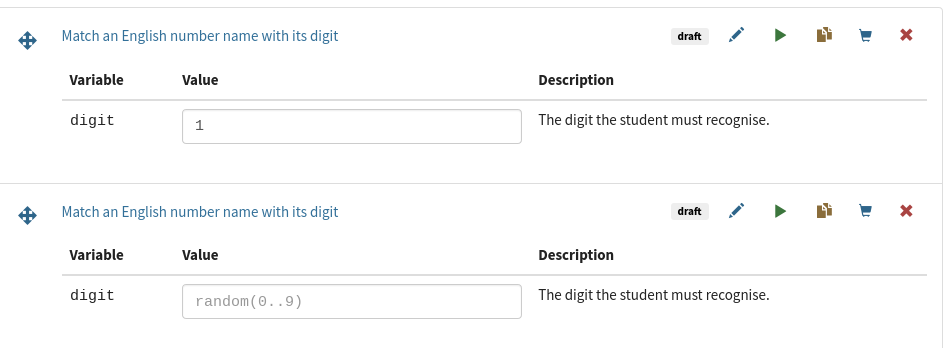
This is actually something we’ve wanted pretty much since Numbas began. Being able to easily customise a template question for a new context will save question authors a lot of time!
I’ve made an exam which uses the variable overrides feature to ask the student progressively more difficult questions about calculating the median of a sample, making sure to show samples which suggest particular errors. See it in the demos project.
Other changes
Enhancements
- If there’s an error during adaptive marking, it’s shown in the part feedback. (issue)
- New JME functions:
frequencies,foldl,scope_case_sensitive. - When you change your answer to a part that you’ve already submitted, the feedback icon next to the input is faded out. (code)
Accessibility
I’ve spent some more time improving the accessibility of the default Numbas theme for keyboard-only and screenreader users.
I’ve also started writing a more detailed accessibility guide for the exam interface, describing how to interact with the Numbas interface and what to expect in different parts of the page.
- The question selectors on the sidebar can be focused with the keyboard. (code)
- Screen readers say “interpreted as” in between the input box and the preview rendering for mathematical expression parts. (issue)
- The ‘main’ landmark on the page just contains the question content, not the sidebar. (code)
- The first link on the page is a “skip to content” link which goes straight to the question content. (code)
- The Numbas logo is no longer announced as a link. (code)
- Individual cells in a matrix input have labels giving their row and column number. (code)
- The part score feedback lines all end with a full stop, so screenreaders pause before reading the next line. (code)
- The score feedback lines no longer have the ARIA role “status”, so they’re not all read out each time the score changes. (code)
Changes
- Division by
dec(0)producesdec("NaN"), notdec("NaN") + dec("NaN")*i. (issue) root(a,b)returns the real-valued root whenais real anda<0. (code)
Bugfixes
- Fixed the
cancelFactorsrule when division is involved. (code) - Fixed a typo in division of complex decimal numbers. (code)
- When a gap-fill part is locked, all the gaps are locked too. (issue)
- When an instance of a custom part type doesn’t specify a value for a recently-added setting, the default value is used. (code)
- The differentiation function
diffaccepts rational numbers as coefficients, and recognisesexp(x). (code) - Choose one from a list parts with drop-down lists aren’t marked as changed on ending the exam. (code)
- Matrix entry parts aren’t marked as changed on ending the exam. (code)
- If conditional visibility causes a paragraph to have no text content, it’s hidden entirely. (code)
- When there’s no feedback, the space where the feedback icon would be isn’t announced by screenreaders. (code)
- If the exam password is just a string of digits, it isn’t padded with decimal zeros. (code)
- It’s no longer possible to bypass the exam password by just pressing Enter in the input field on Safari. (issue)
infer_variable_typesreturns an empty dictionary instead offalsewhen there are no assignments. (code)
Numbas editor
I’ve tagged v6.0 of the Numbas editor on GitHub.
Enhancements
- The question list in the exam editor has been rearranged, showing a single question group at a time, with a separate screen to add a question.
- When adding a variable replacement in adaptive marking, if you try to replace the value of a variable which is not a list with the answer to a gap-fill part, you’re shown a warning that you might mean to use one of the gaps instead. (issue)
- The “insert media” button is in the rich text editor’s toolbar again. (code)
Bugfixes
- Input boxes on longer overflow their bounds. (issue)
- The answer preview for a mathematical expression part’s correct answer highlights variable substitutions. (code)
- The viewport meta tag on the exam/question preview page is now valid. (code)
- The “maximum no. of failures” field in mathematical expression parts is correctly loaded. (issue)
- The extension part type has a “marking settings” tab, so you can set the number of marks available, and other generic part settings. (issue)
Numbas LTI provider
I’ve tagged v2.13 of the Numbas LTI provider on GitHub.
Access changes
Over the past year, because of lockdown, Numbas has been used for a lot more high-stakes summative assessments then ever before.
As a result, we’ve had to deal with lots more requests for deadline extensions, either as an agreed adjustment before an exam starts, or after the fact due to unexpected circumstances. We decided that it was time to add tools to the Numbas LTI provider so these can be handled more easily.
The management pages for a resource on the LTI provider now include an “Access changes” tab. An access change specifies a change to the availability dates, an extension to the duration of an exam, or the number of attempts a student is allowed to make, for a list of students identified either by username or email address.
(Because of the way LTI works, the LTI provider only becomes aware of a student’s existence once they’ve opened a resource, so we can’t provide a searchable list of students for access changes set up before an exam starts. I’m looking into implementing the LTI Names and Roles API, which will let the LTI tool get a list of everyone with access to a resource)
Access changes apply immediately, even when a student is in the middle of an exam. We’ve already used this successfully in the Semester 2 exams that have just finished here at Newcastle.
Read the documentation on access changes.
Docker installation
Not many institutions have the local IT expertise to set up and maintain the Numbas LTI provider software. While I’ve gone to a lot of effort to simplify the installation process, it’s still quite involved and intimidating for someone not used to Linux server administration.
George Stagg and I have put together a recipe for running the LTI provider in Docker containers, which removes a lot of the complication.
Have a look at the Docker installation instructions.
Other changes
Enhancements
- When a student launches a resource that isn’t available to them yet, they’re told when it will become available. (code)
- In the global user search, the key for the corresponding consumer is shown under each user’s name. (code)
Bugfixes
- The ordering on SCORM elements now avoids a rare error when the same element is saved twice simultaneously. (code)
- With the new cookie-checking launch process, some LTI parameters weren’t correctly loaded. (code)
- Fixed a memory leak in the automatic remarking page. It seems to be a lot faster now, too! (code)
- The saved LTI user data is used as the first point of reference when deciding if the user can view a particular attempt. (code)