I’m pleased to announce the release of v10.0 of Numbas.
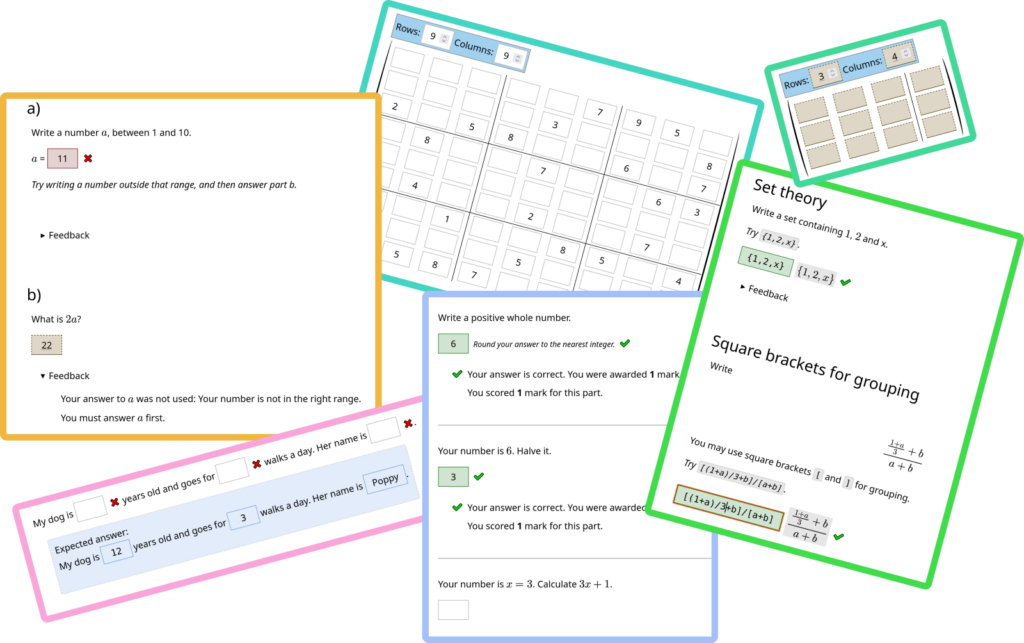
This release adds a new “notations” feature, making it easier to configure how mathematical expressions are interpreted and displayed. There are also several new options to make question parts more versatile, and some changes to avoid rounding errors in numbers.
I’m pleased to announce the release of v9.0 of Numbas. This is a major release with an almost completely rewritten default theme, and some big structural changes inside.
Here’s a round-up of development on the Numbas project over the last couple of months.
The most notable change is the addition of a “due date” field for resources in the Numbas LTI provider, so that late work policies can be accurately applied.
Zach Potthoff took on a “good first issue” from the GitHub repository and added an input hint for number entry parts when the student needs to write a fraction. (issue)
The element numbas.review_allowed from SCORM is used to decide whether to enter review mode on resuming a finished attempt. (code)
Fixed a bug which led to a blank space next to the answer input box when there’s no feedback icon. (issue)
Part feedback messages are always shown when there’s only one part in the question. (code)
The part feedback summary shows when the feedback has changed. (code)
The layout of the part submit and feedback area has changed: on wide viewports, the feedback messages are shown to the left of the “save answer” button and score display. (code)
When auto-submitting a part because the user moved focus away from the input box by clicking inside the same part, the feedback messages are shown. (code)
The objects in Numbas.storage.inputWidgetStorage are documented. (code)
The main question content tries to be as wide as possible, rather than fitting tightly to the content. (code)
In “match choices with answers” parts, the whole cell around a checkbox is clickable. (code)
Some improvements to screen reader part feedback. (issue)
HTML elements with data-interactive="false" can be safely copied and embedded multiple times in the question content. (issue)
The “save all answers” button at the bottom of each question has been removed. It’s unnecessary when answers are automatically submitted, and we thought it was better to always have a “save answer” button next to each part. (issue)
The offline analysis tool now has the ability to review attempts. (code, issue)
Bug fixes
The final part feedback message summing up the the marks awarded is treated separately to messages produced by the marking algorithm, so can be hidden when appropriate. (code)
Somanshu Rath updated the link to the documentation in the README. (code)
Fixed a recently-introduced bug, so expected answers are shown when the question is revealed. (issue)
The menu mode question menu no longer overflows horizontally. (code)
When showing part feedback messages but not answer state, positive or negative messages aren’t shown. (code)
Fixed a bug in the simplification rules for removing brackets involving subtraction. (code)
The gauss_jordan_elimination function always puts the matrix into reduced row-echelon form when possible. (issue)
Parts aren’t generated until rulesets have been generated. (code)
The align attribute on images in question content is translated into corresponding CSS rules on the container when the lightbox button is added. (issue)
Extensions
Geogebra: when linking gaps to geogebra objects, the parent part’s HTML element is used for event handling. (code)
Polynomials: Fixed a typo on Polynomial.pow. (code)
Programming: Submitting with ctrl+enter opens the feedback. (issue)
The main change is an improvement to how scores are reported through LTI 1.3. The completion status of attempts is reported and the “submitted at” time correctly reflects the time the student ended the attempt.
Improved the layout of the access change and resource settings forms. (code)
Improved the Blackboard LTI 1.3 upgrade management command. (code)
Now uses the parser from the compiler to read .exam files. (code)
Here’s an update on Numbas developments since March. We made a separate post announcing the release of v4.0 of the Numbas LTI provider.
We’ve just released v8 of Numbas. There are a couple of technically small but highly noticeable changes to the Numbas runtime: auto-submission of answers and a revamp of the exam feedback settings.
We’ve just released a new major version of the Numbas LTI provider.
This release adds support for LTI 1.3. This is a new version of the LTI protocol, supported by all major virtual learning environments and providing new features.
We’ve also taken the opportunity to completely redesign the user interface from scratch, with a focus on accessibility and ease of use.
I’ve made a short video describing the changes in this version:
Here’s a development update, covering everything that’s changed since November.
Most of my work has been on adding LTI 1.3 support to the Numbas LTI provider. We hope to have that ready to use by the summer, in time for the next academic year.
The rest of the development work has been mainly bug fixes, with a couple of new features in the Numbas runtime.
Here’s a development update, covering everything that’s changed since July.
I spent a lot of time on the Summer working on our other project, Chirun. I wrote a new LTI 1.3-compliant tool, to make it easier to embed Chirun material in our virtual learning environment. That’s now in use at Newcastle, and I’m looking for other institutions to test it with virtual learning environments other than Canvas or Moodle. Our intention is to make our server available to everyone, since it won’t handle any personally identifying information.
So it’s been a while since I had time to do a Numbas development update. There have been quite a few bug fixes and an encouraging number of contributions from other people. The main news is that the Numbas runtime is now WCAG 2.1 AAA compliant.