Here’s an update on Numbas development, covering December 2021 to March 2022. Sorry about the long gap between posts – holidays, strikes, exams and finally catching covid didn’t leave me much time for blogging!
In February, I wrote about our new extension for assessing programming. In order to implement this, I added a framework for running asynchronous tasks before marking a question part, and for defining new kinds of input method. These should both open up all sorts of possibilities beyond the programming extension.
In the editor, I’ve been working on adding a “queues” feature to projects. The main motivation is to support the Open Resource Library, but I’ve already thought of a few other use cases for it.
Pre-submit tasks
Numbas has always assumed that a student’s answer can be marked immediately, as soon as they press the “Submit” button. That’s true when all of the logic is done internally, but wasn’t possible for marking code, when we have to call out to a separate process that might take a long time to return a result.
We tried a few ways of getting round this. I eventually came up with a framework for “pre-submit tasks”, which I think is sufficiently abstract to support a variety of uses:
- A part’s marking algorithm can define a note called
pre_submit, which gives a list of tasks to run. - When the part is submitted, if there are any pre-submit tasks, they’re run and the rest of the submit method is aborted.
- Once the tasks have finished, the submit method runs again, filling in the
pre_submitnote with the values returned by the tasks. - Results are cached, so if you submit the same answer twice, the tasks aren’t run again. This means that when you re-open an attempt, Numbas doesn’t have to run all the tasks again.
This isolates the asynchronous weirdness to one bit of the marking algorithm, and means everything else can work as normal. I think this is a good solution.
As well as executing code, this could be used to call out to external services, or to inspect interactive elements embedded in a question, such as a GeoGebra worksheet. At the moment the GeoGebra and JSXGraph extensions do their own stuff around inspecting diagrams during marking, and I’d like to replace these with pre-submit tasks.
There’s a section on pre-submit tasks in the marking algorithms documentation.
Custom input methods
For the programming extension we also needed a code editor input widget. Our early prototypes hacked this in by replacing the default text input with a code editor after the question has loaded, but I wanted a better solution.
There is now a JavaScript interface for extensions to define new input widgets which can be used by custom part types.
When registering an input widget, the extension must provide:
- A list of options that the part type can set.
- Functions to fill in the widget with a given answer, and to report a changed answer when the student uses the widget.
- A function to create the HTML for the widget.
- Functions to save and restore the state of the widget for when an attempt is resumed.
I think this makes it a lot easier to do more inventive stuff with Numbas. I’m looking forward to having a go at implementing some of the common graphical input methods like “hot spot” images and sorting activities, without the pressure of putting them in the core Numbas code.
There’s some info on how to do this in the Numbas JS API docs, though looking at how the programming extension defines the code editor widget might be more helpful.
Queues
A queue is a list of items in the editor that need some kind of attention. A queue belongs to a project, though items from anywhere in the editor can be submitted to a queue. Once an item has been submitted to a queue, it gets a comments thread for discussion and a checklist to help reviewers keep track of what needs to be done.
The initial motivation for this was to support the Numbas Open Resource Library: the plan is that people will submit material for inclusion in the library to a queue, and the library’s moderators will use the queue to go through the process of checking that the material is suitable.
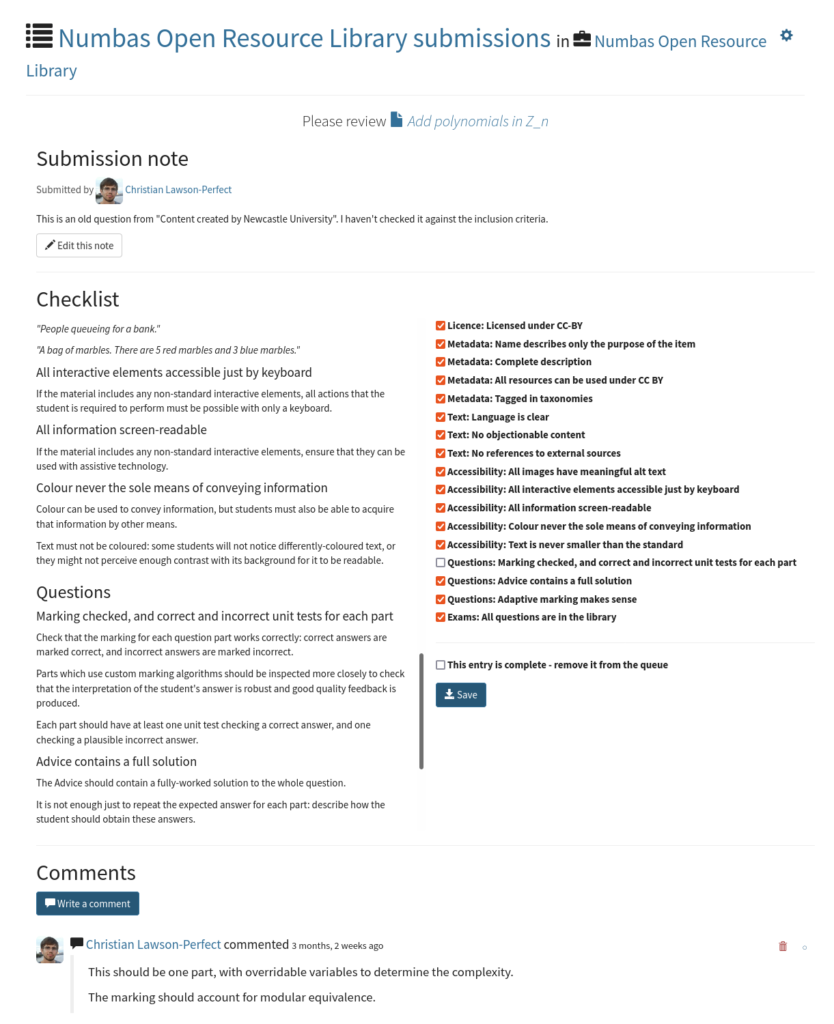
Queues could also be useful as a means of getting expert help: we’re going to set up a queue for colleagues at Newcastle to submit items that they’d like to be checked by the e-learning unit before delivering to students. You could do the same at your institution.
Graph theory extension
I was asked to write some questions for a module on graph theory, so I’ve written an extension to generate, manipulate and draw graphs.
The most important function it provides is to draw randomly-generated graphs, using the CoLa layout engine to produce something reasonable-looking.
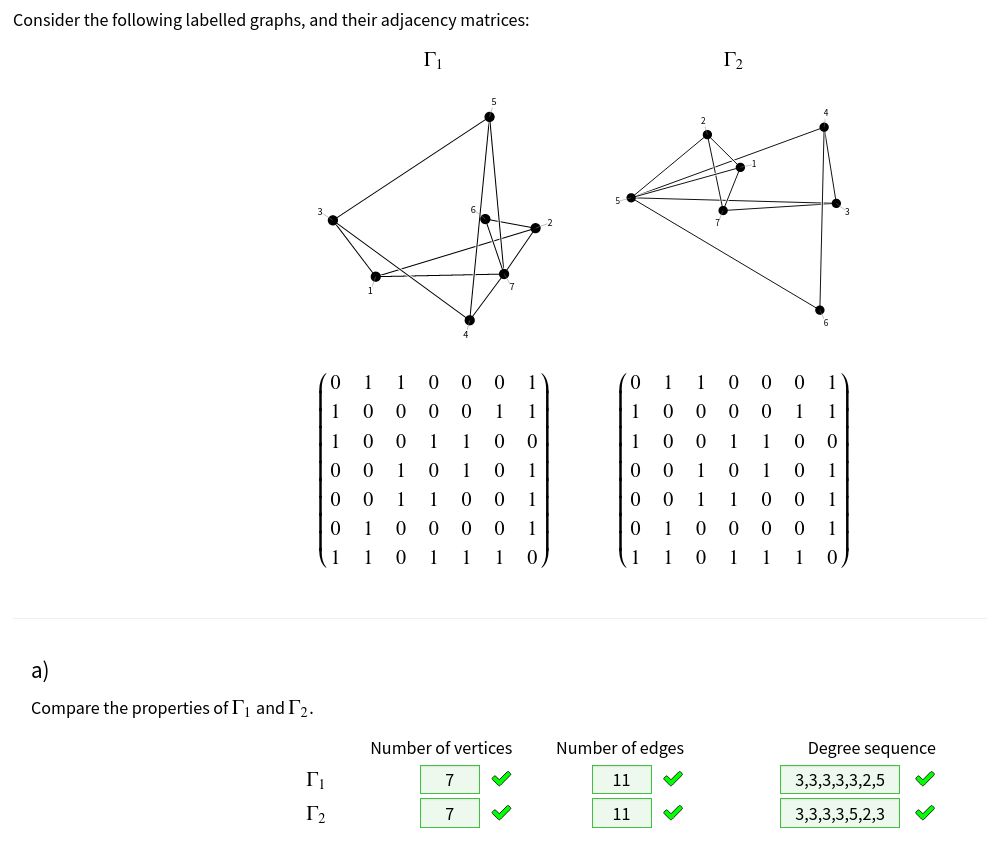
The extension has functions to create a graph from an adjacency matrix, or from lists of vertices and edges. You can label edges and vertices, or draw edges in different styles. There are operations to modify or combine graphs: you can take subgraphs, make the union, Cartesian product or direct product of two graphs, and find connected components.
I’ve put together a small demo exam containing four of the questions we’ve written so far. Later I hope to put together a proper demo, specifically written to show how to use the extension.
The Prim’s algorithm question has a full description of the steps of the algorithm in the advice, which prompted my next strand of development:
Working-out
Working on the graph theory extension made me think again about how to make it easier to display working-out.
The “Advice” section of a question should describe exactly how to answer the question. This is often quite hard to write, particularly when you have to follow a procedure with a variable number of steps.
I thought about what tools would make it easier to produce this kind of step-by-step working-out.
A pattern I’ve used a couple of times, in the optimisation and graph theory extensions, is to write an “annotated” function to carry out an algorithm, which produces a series of “frames” as well as the final result. The code to carry out the algorithm can at any point produce a “frame”, which captures the algorithm’s current state along with some explanatory text.
The extensions do all this in JavaScript, but I’d really like to be able to do the same thing in JME. I think that we’d need some new syntax to produce code that is easy to read and to write.
I’ve been collecting my thoughts in a GitHub issue, and I’ve written a prototype extension to try out some of my ideas. If you’re interested to follow along, I have an untidy prototype question where I’ve tried out a few different algorithms.
As an example, this code:
working_out(
[
["$a$",x],
["$b$",y],
["$a \\mod b$",r],
["Equation",
"$"+latex(
substitute(
["a":x,"b":y,"m":m,"r":r],
expression("a = m*b+r")
)
)+"$"
]
],
let([gcd,x,y],
iterate_until(
let(
r, mod(x,y)
,
m, (x-r)/y
,
[y,r]
; comment(
"$"+y+"$ goes into $"+x+"$ $"
+(m as "number")+"$ "+pluralise(m,"time","times")
+" with remainder $"+r+"$.")
)
,
[x,y]
,
[a,b]
,
mod(x,y)=0
),
gcd
)
)produces the following display:

The idea is that the working_out function sets up an environment where annotations on steps of the algorithm can be collected, producing a table showing the steps. The first argument is a list of extra columns the table should have, and the values they should contain, in terms of the algorithm’s variables. The second argument is code to run the algorithm; the comment function records a step of the algorithm along with some explanatory text.
In order to make this easier both to read and write, I think we need some new syntax for procedural algorithms. I’ve put some ideas of what that might look like in the GitHub issue.
It needs more work, but I think this will be a useful tool!
Numbas runtime
I’ve tagged v6.2 of the Numbas runtime on GitHub.
Enhancements
- Jesse Hoobergs improved the compiler so that it can minify all the javascript and css files. (issue)
- When a JavaScript error is produced, Numbas uses the standard Error type so that browsers can show a full stack trace. (issue)
- Variable replacements when moving to a next part in explore mode can use the credit awarded for the current part. (code)
- The
htmlfunction substitutes variables into the content of the returned element. (code) - The
imagefunction substitutes variables into SVG images. (code) - The
imagefunction can be given the width and height that the image should be displayed at, in em units. (code) - The matrix answer widget for custom part types has options to show or hide the brackets, and you can give lists of headers for the rows and columns. (issue, documentation)
- The
formatnumberfunction now has a definition fordecimalvalues, so they’re not rounded down tonumbervalues first. (issue)
Changes
- Extensions can contain a folder called
standalone_scripts– files in that folder won’t be collated into the main scripts file when the exam is compiled. (issue) - Unicode superscript digit characters are interpreted in JME as exponentiation. (issue, docs)
- Jesse Hoobergs changed the Diagnosys algorithm to offer an “End the test option, rather than automatically ending once every topic has been assessed. (issue)
- The
m_anywherepattern-matching function turns on the “allow other terms” flag automatically. (code) - On the exam results screen, the feedback message is only shown if the “show current score” option is turned on. (code)
- The
feedbackfunction in marking algorithms can take an HTML value instead of a string. I used this to display charts generated by the programming extension. (code) rationalJME values prefer to convert to thedecimaltype overnumber, with the aim of maintaining as much precision as possible. (code)
Bug fixes
- The code to find variables used inside strings of text correctly deals with \simplify commands in TeX. (code)
- Jesse Hoobergs fixed a bug with diagnostic mode exams, so the state is updated correctly if the exam ends due to no more options. (issue)
- Trailing commas are allowed at the end of dictionaries. (issue)
- When a part with a custom
markmethod fails with an error, it’s handled properly instead of crashing Numbas. (code) - A couple of edge cases in the JME signature parser are caught. (code)
- A part’s credit is explicitly set to 0 before applying feedback. (code)
- When a diagnostic test ends, the SCORM data is saved, so the attempt is marked as “completed”. (issue)
- The output of the functions
tobinary,tooctal,tohexadecimalandtobaseare marked as LaTeX, so they’re displayed nicely. (code) - The matrix answer widget ensures that the content of each cell is a string before parsing it. (code)
- The core JME code always uses the current scope’s parser instead of the default one. (code)
- I rewrote the routine to find the length of the contents of an input box, used to resize the input automatically. It’s much, much faster now. (issue)
- The code to find variable dependencies was run before custom function definitions were used, so variables used in custom functions weren’t accounted for. (code)
- Question variables with HTML values containing LaTeX weren’t restored properly. Now, the HTML code is stored at the moment the variable is evaluated, before MathJax runs, so that any subsequent changes are not saved to the attempt suspend data. (issue)
Numbas editor
I’ve tagged v6.2 of the Numbas editor on GitHub.
Enhancements
- The question editor shows a message under variables that were automatically created because they were referred to somewhere in the question. (code)
- There are separate settings for minifiers for JS and CSS. (code)
- When you move to edit a variable, its row in the preview table is scrolled into view. (issue)
- Vastly sped up the database query to fetch extensions used by a question. (code)
Changes
- In a part’s “marking algorithm” tab, your answer is only submitted when you press a “Submit” button, instead of automatically as you type. (code)
- The theme and extension editors only list files in the current directory, and show links to go up or down in the directory hierarchy. (code)
- In the theme and extension editors, the button to upload a replacement of the current file is labelled “Upload” instead of “Save”, to differentiate it from the button that saves the contents of the text editor. (code)
- The project index page now shows some of the project’s content above the activity timeline: any folders at the top level, and up to three of the most recently-edited questions or exams. (issue)
Bug fixes
- Marking algorithm notes are no longer picked up by the variable dependency checker as variables that need to be defined. (issue)
- Custom part types that you’ve been given individual access to are shown in the question editor. (code)
- Automatic creation of variables is throttled, to stop the editor becoming unresponsive while you type. (code)
- When you copy an item, its tags, taxonomy nodes and ability levels are copied too. (issue)
- Items with the licence setting “all rights reserved” can be copied by users with editing access. (issue)
- The preview of the expected answer for mathematical expression parts deals with variable substitution properly while expanding juxtapositions. (code)
- The code to check for duplicate variable names was running too often, slowing down the editor. (code)
- The “checking range” expression field for mathematical expression parts knows that
vRangeis defined and isn’t a question variable. (code) - Fixed a big memory leak in the exam editor. (code)
Documentation
- The documentation now uses the sphinx-book theme.
- There’s now a separate page on first-party extensions (i.e. those written by me), since there are so many of them.
- The page on JME lists the synonymous keywords and characters supported by the parser.
Numbas LTI provider
I’ve tagged v3.1 of the Numbas LTI provider on GitHub.
Enhancements
- While a student is attempting an exam with an “available until” date, a banner is shown with the time that the exam will automatically close. (issue)
- If the request to save data on ending an attempt fails, there’s a “Try again” button that the student can click. (code)
- The automatic re-marking page shows the start time of each attempt, and you can sort the attempts by student name, start time, or total score. (code)
- The attempt timeline shows a loading message instead of “there’s no data for this attempt” while the data is being loaded. (issue)
Changes
- Automatic re-marking always uses the data model as it was before any other re-marking, so that changes introduced by previous re-markings don’t affect the results. (issue)
- When manually changing the scores for an attempt, you can specify scores to 2 decimal places. (issue)
- Automatic re-marking is now labelled “re-mark”, and manually changing part scores is now labelled “change scores”. Both were previously labelled “remark”. (code)
Bug fixes
- Fixed how
first_setup.pysets theSECURE_SSL_REDIRECTsetting. (code) - Replaced
ugettextin the code withgettext, so it works with django 4.0. (code) - All tasks triggered by model signals are delayed slightly. The motivation for this was to avoid reporting incorrect scores back to the consumer, while an attempt is being ended. (issue)
- If there are two database records to remark the same part, the latest one is used. (code)
- The resource dashboard only counts users with non-deleted attempts when showing how many users have attempted the resource. (code)
- When automatically re-marking attempts, the new suspend data is saved, so that any changed values are shown when reviewing the attempt. (issue)
Documentation
- I’ve removed the Heroku installation instructions. Heroku no longer provides free non-ephemeral storage, so it’s not straightforward to set up a functioning instance of the LTI provider.
Extensions
JSXGraph
- Boards that haven’t been rendered when the attempt data is saved are correctly saved. (issue)
- The extension uses JSXGraph v1.4.1.
GeoGebra
- Fixed a bug (potentially in GeoGebra itself!) which caused applets loaded from a file to be zero pixels high. (code)
Permutations
- Added a function
cycle()to produce a single cycle permutation. (code, documentation)
Eukleides
- Documented the bounding box parameters for the
eukleidesfunction. (documentation) - Fixed the order of the arguments in
rotate(point,origin,angle). (code)
Statistics
- Properly documented all of the functions, instead of referring to the jStat documentation. (documentation)