Here’s a development update, covering everything since the release of Numbas v7 last December.
Progress on Numbas has continued fairly quietly, while I’ve had to split my attention between this, Chirun, and other stuff at Newcastle.
I gave a talk at EAMS 2023 with an update on developments over the last year:
Numbas runtime
I’ve tagged v7.1 of the Numbas runtime on GitHub.
Spreadsheets extension
I’ve written an extension which adds a data type and functions for working with, displaying and editing spreadsheets, or tables of data.
I was motivated to write this extension by my colleague Chris Pearson from the school of engineering, who has written questions where students have to fill in a replica of a levelling table, implemented as a gap-fill with hundreds of gaps.
Those questions are not pleasant to work with, so I thought that we needed a better way of dealing with spreadsheet-like tables.
With the spreadsheets extension, you can upload a .xlsx file from Excel into a question variable definition, and then fill it in or change the styling of cells using JME functions. You can display static spreadsheets to the student, but more excitingly there’s a “Spreadsheet” custom part type where you give the student a spreadsheet to fill in and can mark their answers.
I can see this extension being really useful for courses outside the pure maths topics that Numbas has typically been best at. Tables are a really common way of working with data!
I’ve made an exam with a few demo questions.
Improvements to the printable worksheet theme
Laura and I spent some time rejigging the “printable worksheet” theme. It hadn’t had much attention since I first wrote it over a decade ago. We made the interface a bit tidier and easier to understand, and added some features.

You can now choose to show question content on the answer sheet. This is useful for questions with parts that have expected answers, so you don’t have to repeat the expected answer in the Advice section.
There are controls for the page margins, and all the display options from the default theme are there, which should help students who need bigger text or a particular colour combination.
Handling more Unicode characters
Over the years we’ve had sporadic reports of students writing unusual characters in answer boxes, causing errors when Numbas can’t interpret them.
Usually this is because the student’s keyboard layout isn’t the standard UK one we work with, and it produces variants of characters such as carets, brackets and dashes that are more appropriate for the student’s home language.
The other main cause of input errors was when students would copy a mathematical symbol either from a LaTeX rendering in a content area, or by searching for the symbol because they don’t know how to type the name that Numbas understands.
Text in a web browser is encoded using Unicode, the universal standard for representing writing digitally. Unicode is enormous: at the moment it contains 149,186 characters, representing all sorts of glyphs such as letters, symbols, ideograms, punctuation, and emoji.
So I’d been putting off really tackling this issue properly. I’ve added in support for various Unicode characters as they come to our attention, but I’d prefer to get ahead of the game and anticipate the kinds of characters that might come up.
I noticed that the STACK people were having the same sorts of problems, so I decided it would be worthwhile to spend a few days looking very closely at the mathematical parts of Unicode, and working out how to map them onto the existing syntax recognised by our two systems.
I wrote some Python code to help me work through each category of Unicode characters. There’s a standard algorithm for normalising characters onto a subset of the whole: this deals with most sets of characters that are just minor variations on a more common character, but it’s not completely consistent. For the remaining characters, I had to look through each of them and decide how they should be interpreted.
My code, and the tables of character mappings, are available in the Unicode math normalization project. The mappings have been integrated into Numbas’s JME system, so you can write expressions like √❪3² + 4²❫ and Numbas knows what to do.
Offline attempt analysis
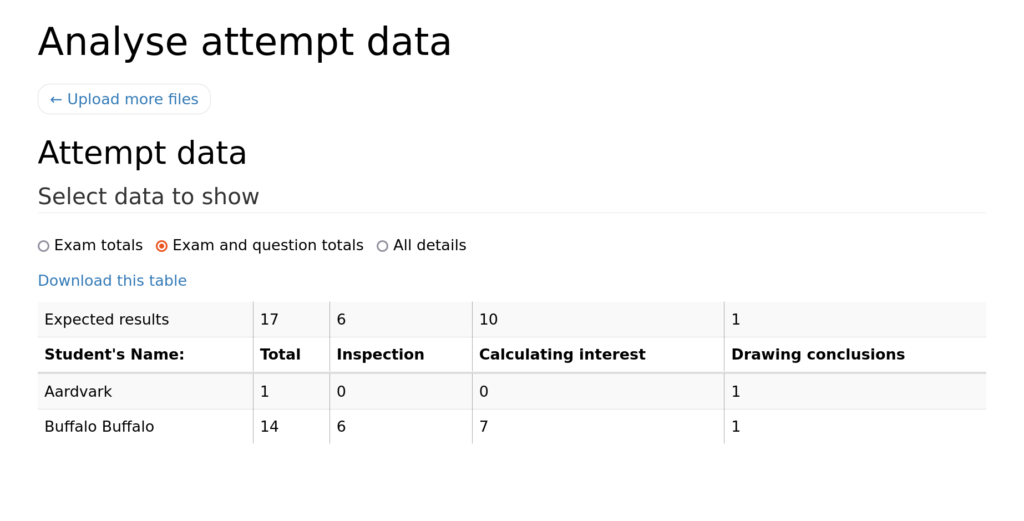
Laura has added a system for generating a file containing all the data for an attempt, that a student can download once they’ve finished an exam. There’s a tool included in the exam package (and available through the editor) that can load these files, and show you a table of results for a whole class of students.
The motivation for this feature is to support teachers, usually in secondary schools, who don’t have access to a proper virtual learning environment but would like to use students’ scores on Numbas tests as part of their assessment.
There’s some info in the documentation on how to use this.
Other changes
Enhancements
- Matrix and vector values can have complex number entries. (code)
- You can now give a generic message to show at the end of the exam. (documentation)
- There are new JME functions
lu_decomposition,gauss_jordan_eliminationandinversefor the common matrix operations. - There’s now dedicated code to make substitutions into JME expressions, instead of using the generic string substitution. (issue)
- When rendering negative number tokens to JME, they’re bracketed as if they’re a unary minus operator applied to a positive number. (code)
- Added some unit tests for pre-submit tasks. (code)
- If
Numbas.load_pre_submit_cacheisfalse, then cached results for pre-submit tasks aren’t used. This is used by the LTI provider. (issue) - Taking an
integervalue to the power of adecimalvalue produces adecimalvalue instead of a less-precisenumber. (issue) - Leaving the “maximum marks” field for a part empty is equivalent to setting it to zero. (issue)
- You get a “correct answer is missing” error when the “expected answer” field for a mathematical expression part is empty, instead of a cryptic code trace. (issue)
- When reviewing an attempt, you’re always able to move to any question, regardless of the “Allow move to previous question?” exam setting. (issue)
- In “match choices with answers” parts, clicking anywhere in the cell corresponding to a choice selects that choice. (issue)
- When the answer input box for a gap would be too wide, a scrollbar is shown. (issue)
- Variables are substituted into the alt text for images without requiring the
eval-altattribute. (issue) - If the question author doesn’t give TeX code for a custom constant, its name is used. (issue)
- Christian Arteaga updated the Spanish translation. Thanks!
- There’s a new JME function
with_precisionwhich adds precision information to a number value. (This is added automatically by functions likeprecroundandsiground). (documentation) - In JavaScript, the version of the Numbas runtime is stored in
Numbas.version. (code) - The
truncfunction can now take an optional number of decimal places to truncate to. Thanks to Anurag Raut. (issue, documentation) - In JavaScript, the
valueattribute of aTHTMLtoken is a plain array instead of a jQuery object. (code) - The expression
root(x,2)is rendered to LaTeX in the same way assqrt(x). (issue) - When the gaps in a gap-fill part have different types, the “sort student’s answers before marking?” option is ignored. (issue)
- Questions containing only “information only” parts don’t count towards the number of questions shown on the front page. (issue)
- In “sequence” mode exams, there’s now a link on the sidebar to view the exam introduction again. (issue)
- The code repository now contains a settings file for the “Can I also use?” tool, documenting browser features used by Numbas with the default theme. (code)
- Strings produced by the
currencyfunction are marked as valid LaTeX, and dollar signs in rendered LaTeX are escaped. (code) - There is now a “pipe” operator
|>which you can use to chain a series of transformations of a single value. (documentation) - In the mathematical expression part’s marking algorithm, the
formula_typenote is"number"by default, if automatic inference fails. (code) - The function
transposenow works on lists of lists. (code, documentation)
Bug fixes
- Fixed a bug with custom JavaScript functions so they have access to environment variables such as
question. (code) - The attempt resume process doesn’t try to load deterministic variables. (code)
- Fixed a bug where variables with names containing capital letters weren’t saved. (code)
- Fixed the definition of the
random_integer_partitionfunction. (code) - Fixed a bug with bracketing operators during rendering to JME. (issue)
- Question variable definitions are always converted to a string. (code)
- Questions with custom constants don’t restore variables until the constants have been defined. (issue)
- When the “number” answer input widget’s value is a fraction, it isn’t run through the decimal number cleaning routine. (code)
- Fixed a typo in
Numbas.jme.enumerate_signatures. - Disabled answer widgets never report changes. (code)
- When converting a range to a list, the
decimaldata type is used so that rounding errors aren’t introduced. (issue) - The precision of a number-valued question variable is now saved correctly. (issue)
- In a diagnostic-mode exam. the “after exam ended” note is not re-evaluated on resuming the attempt. (issue)
- Fixed slicing a matrix by a range. (issue)
- The printed worksheet theme no longer prints the names of extensions used at the end of each question. (issue)
- The default theme no longer overrides browser default outlines for focused elements. (code)
- Fixed the definition of exponentiation in
decimalvalues when the base is a negative real number. (issue) - When working out the number of elements in a range, some floating-point error is tolerated. (code)
- The value definition for a custom constant is always converted to a string. (code)
Extensions
- Updated to v1.5.0 of the JSXGraph library. (code)
Numbas editor
I’ve tagged v7.1 of the Numbas editor on GitHub.
Custom variable templates in the variable editor
In order to make working with spreadsheets straightforward, I needed a way of uploading a .xlsx file to the question editor and using it with question variables.
I’ve added an API for extensions to register new variable template types. This lets you present an interactive component to the question author, and generate a corresponding JME variable definition.
I can see this being useful for other extensions; there could be an interactive tool to draw diagrams, for example. See the documentation for more info.
Other changes
Enhancements
- Any variable type that can be converted to HTML causes the warning about HTML nodes to be shown in the variable editor. (code, issue)
- Accounts can have a permission
editor.view_everythingwhich gives them read access to everything in the database. (code) - Thanks to Maanas Arora, when matrix or vector values are displayed, they’re shown as “Matrix/Vector of N items” instead of “List of N items”. (issue)
- Again thanks to Maanas Arora, the first setup form fills in the “Python executable field” automatically. (issue)
- The URL
/.well-known/change-passwordis now supported. (code, info on this well-known URL) - In the part testing tab, the feedback area adds a scrollbar when messages are too wide. (issue)
- If you upload a zip file whose contents are wrapped in a container directory, the container is unwrapped. This allows you to upload zip files of extensions directly from GitHub. (issue)
- Laura wrote some documentation about how to use the Django admin interface to manage extensions. (issue, documentation)
- On the editor item preview page, you can create a link to open the item in the Numbas lockdown app, after you specify a password. (code, documentation)
- The logic to deactivate a user account has been moved to a function,
accounts.models.deactivate_user, which can be used from the Python shell or scripts. (code) - The Testing tab for an Extension part renders the part’s prompt so that you can interact with it and submit an answer. (issue)
Bug fixes
- Fixed detection of AJAX requests following a change in Django. (code)
- Fixed a typo in the method to delete a folder in a project. (code)
- When showing the dimensions of a matrix, the
.rowsand.columnsattributes are used instead of looking at the underlying list objects. (code) - CSS stylesheets provided by extensions are loaded in the question editor. (code)
- Fixed a bug that caused the custom part type editor to make a save request as soon as it loads. (code)
- The variable
part_path, defined in marking scripts, is recognised as an existing variable by the reference finder. (code)
Numbas LTI provider
I’ve tagged v3.3 of the Numbas LTI provider.
There’s hardly been any activity on the Numbas LTI provider lately. It’s running smoothly!
In the medium term we’ll need to add support for LTI 1.3 Advantage, as LMSes drop support for LTI 1.1. I expect this to be quite complicated, but I’ve got my head round LTI 1.3 by rewriting the Chirun LTI tool, so I know what I’m doing, at least.
Enhancements
- The Docker setup now has settings for configuring how email is sent. (code)
Bug fixes
- The pre-submit cache is cleared before re-marking question parts, so that they’re really re-evaluated. (issue)
- The Docker setup always restarts the postgres, redis and nginx containers automatically. (code)
- The maximum length for the
lis_result_sourcedidandlis_person_sourcedidLTI parameters has been increased. (code)